A couple of months ago, corteza was an agent harness in R you could hand to an LLM, as long as you fed it an API key and watched the per-token meter tick. As of this week you can point it at your Claude Pro/Max or ChatGPT subscription instead. No API key and no per-token billing. And it’s all on CRAN!
Here’s the stack and what changed.
| Package | Version | Highlight |
|---|---|---|
| tinyoauth | 0.1.1 | Claude Code and Codex OAuth login routes |
| llm.api | 0.1.8 | subscription providers, provider-native web search |
| corteza | 0.7.0 | subscription auth in the agent loop, hardened approvals |
| pensar | 0.6.4 | incremental vault export |
| saber | 0.7.2 | context engineering for agents (covered here) |
Running a subscription, not an API key
The two new providers are openai_codex (your ChatGPT subscription, through the Codex Responses endpoint) and anthropic_claude (your Claude subscription, through the Messages API). Both authenticate with OAuth, not a key. You log in once:
llm.api::claude_oauth_login() # or openai_codex_login()
It prints a URL, you approve it in a browser, paste the code back, and the token caches. From then on it’s just another provider:
llm.api::chat("Explain tail recursion", provider = "anthropic_claude")
corteza::chat(provider = "anthropic_claude")
corteza picks the token up automatically, so the agent loop, tool calls and all, runs on your subscription.
The part where Anthropic changed its mind
This was, briefly, on shakier ground. Anthropic had announced that the Claude Agent SDK, claude -p, and third-party apps built on it would stop drawing from subscription rate limits and move to a separate monthly credit. Then, on the day it was due to take effect, they delayed it, saying they’re reworking the plan to better support how people build on Claude subscriptions. So for now, harnesses like this keep running on your subscription, with advance notice promised before anything changes.
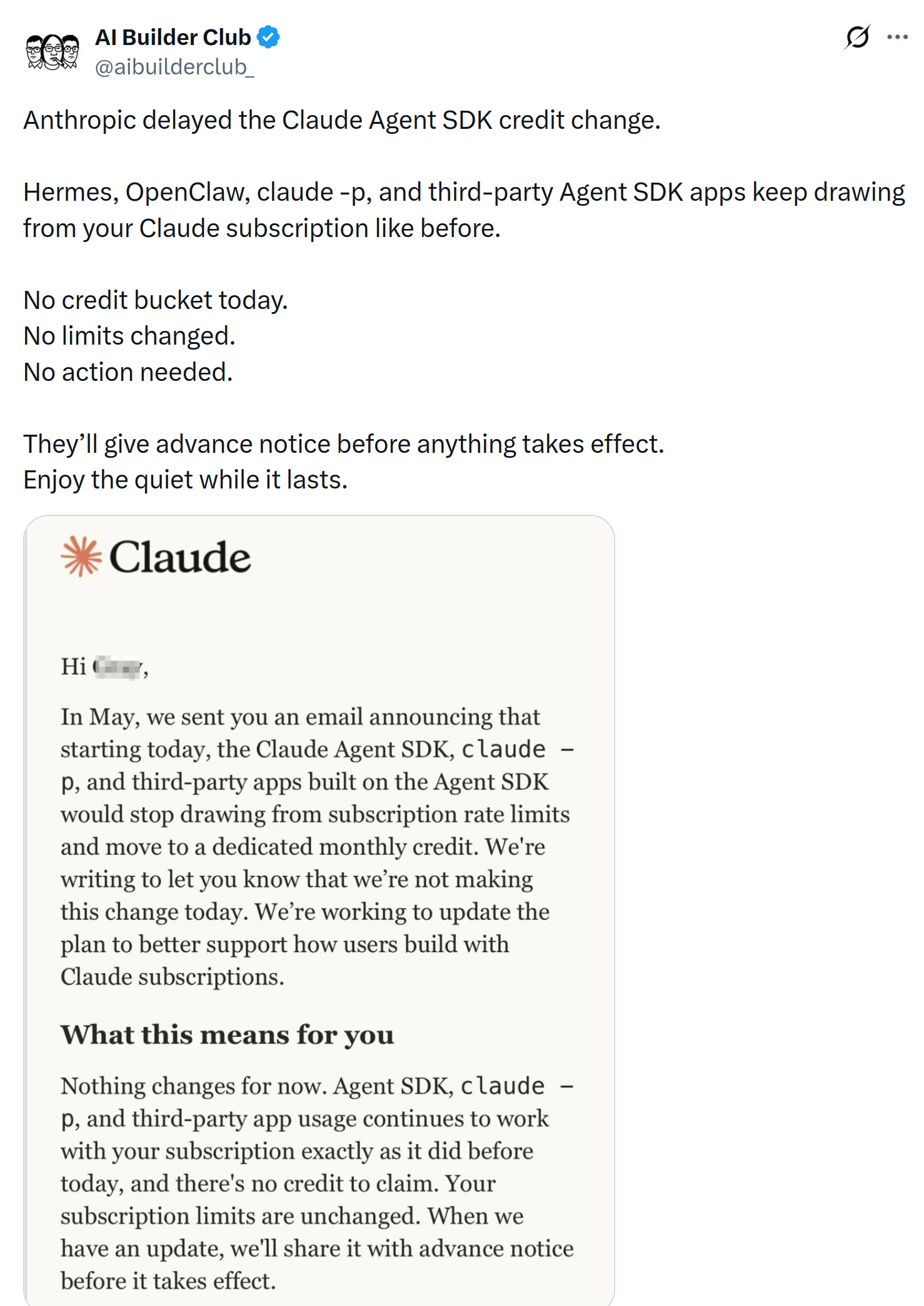
Via @aibuilderclub_ on X.
tinyoauth 0.1.1, the OAuth under all of it
None of the above works without the login flow, and that lives in tinyoauth: a dependency-light OAuth 2.0 client built on curl, jsonlite, and base R’s own socket server for the redirect listener. No heavier HTTP stack.
0.1.1 adds the Anthropic Claude Code OAuth route (PKCE login, the right scopes, token caching and refresh) alongside the OpenAI device-login flow that the Codex provider already used. That’s the whole reason anthropic_claude and openai_codex can hand llm.api a bearer token instead of asking you for a key.
llm.api 0.1.8, the client
llm.api is the minimal-dependency LLM client the providers plug into: base R, curl, jsonlite, and now tinyoauth. Beyond the two subscription providers, this cycle brought:
- Provider-native web search. A
web_searchtoggle onchat()andagent()that runs the model’s own server-side search (Anthropic, OpenAI, Moonshot, Codex), returning citations, instead of bolting a separate search API onto the side. - Per-call tool context. An
agent()tool_handlercan read a read-only snapshot of the turn (the model’s own narration, the call index) so a harness can show why a tool is about to run at approval time. - Cost in
usage$cost. Everychat()/agent()return prices itself from a bundled per-model snapshot, cache rates included.
A late-cycle fix (0.1.8) was the one that mattered most for corteza: the anthropic_claude agent loop was building a malformed request after the first tool call. chat() was fine; tool use wasn’t. It’s fixed, which is why corteza requires llm.api (>= 0.1.8).
corteza 0.7.0, the agent
corteza is the runtime that ties it together: it gives an LLM a live, persistent R session with policy-gated tool use, over three surfaces (a console REPL, a shell CLI, and an MCP server). 0.7.0 wires in the subscription providers and hardens the parts that touch you:
- The approval prompt now sanitizes every model-controlled field it renders, so a crafted path or tool name can’t forge a fake “Reason:” line in front of you.
/compactsurvives provider-native history shapes (including role-less Codex Responses entries), so a wedged session can actually be recovered.- Self-bounding tools (shell, child R, network) use their own timeouts instead of a fragile R-level one.
pensar and saber, the supporting cast
pensar 0.6.4 (the LLM wiki engine) makes vault_export() incremental: edit a few pages and it re-renders a handful instead of the whole vault, tracking changed wikilinks so broken and resolved links stay correct. It also exports default_vault() so you can confirm which vault a bare ingest() will act on.
saber 0.7.2 (AST symbol indices, blast-radius tracing, project briefings) is the context-engineering layer the agent leans on. Its changes shipped with the toolchain update earlier this week.
Thanks
The provider-native search idea isn’t mine. Hadley Wickham made the point in “Your LLM can’t math (and that’s ok)” that the providers already ship their own tools, search included, so you can reach for those without the previously required Tavily API key. The web_search toggle is that, taken literally.
And thanks to Sounkou Mahamane Toure, whose OpenAI Codex provider PR got subscription auth working in the first place! The OAuth half of that PR is what I lifted out into tinyoauth. Sounkou lit a fire that got Claude subscriptions in there too.
Install
corteza pulls llm.api (and through it tinyoauth) and saber in as dependencies, so it’s really two installs: the agent plus the wiki engine.
install.packages(c("corteza", "pensar"))